InnovatorBench: Evaluating Agents for Innovative LLM Research
From the AI revolution sparked by AlphaGo to the language breakthroughs unleashed by GPT series, artificial intelligence is evolving from “answering questions” to “getting things done,” and ultimately being able to conduct scientific discovery autonomously.
But here’s the big question—when AI agents start doing research that lasts for days, how do we measure their scientific capabilities?
Therefore, We unveil the benchmark: InnovatorBench—the first systematic evaluation framework for AI Research Agents’ innovative capabilities in day-long scientific research, complete with ResearchGym, an environment that lets AI agents conduct research autonomously in a more realistic scenario.

- 🔗 Paper’s link:https://github.com/GAIR-NLP/InnovatorBench/blob/main/resources/InnovatorBench.pdf
- 💻 Project page:https://ai-innovator.opensii.ai/
- 🔗 Github page:https://github.com/GAIR-NLP/InnovatorBench
Background: The Evaluation Crisis in the Age of Research Agents
Current AI research benchmarks (like PaperBench) mostly test single-dimensional capabilities like reproducing paper results or writing code.
But this is far away from real scientific research: Science isn’t about executing tasks, it’s about constant exploration, adaptation, and innovation.
The limitations of these traditional benchmarks include:
- Narrow task scope: Single tasks only measure code implementation or parameter tuning, missing the full research workflow;
- Unrealistic environments: Missing essential research conditions like distributed training and web search;
- Lack of innovation: Tasks aim to “reproduce existing results” rather than developing new methods;
- Short timeframes: Experiments limited to hours or even minutes, unable to measure true long-term reasoning and decision-making.
Therefore, previous benchmarks failed to quantify and evaluate a crucial question: Can AI research agents complete the full research cycle as human scientists do?
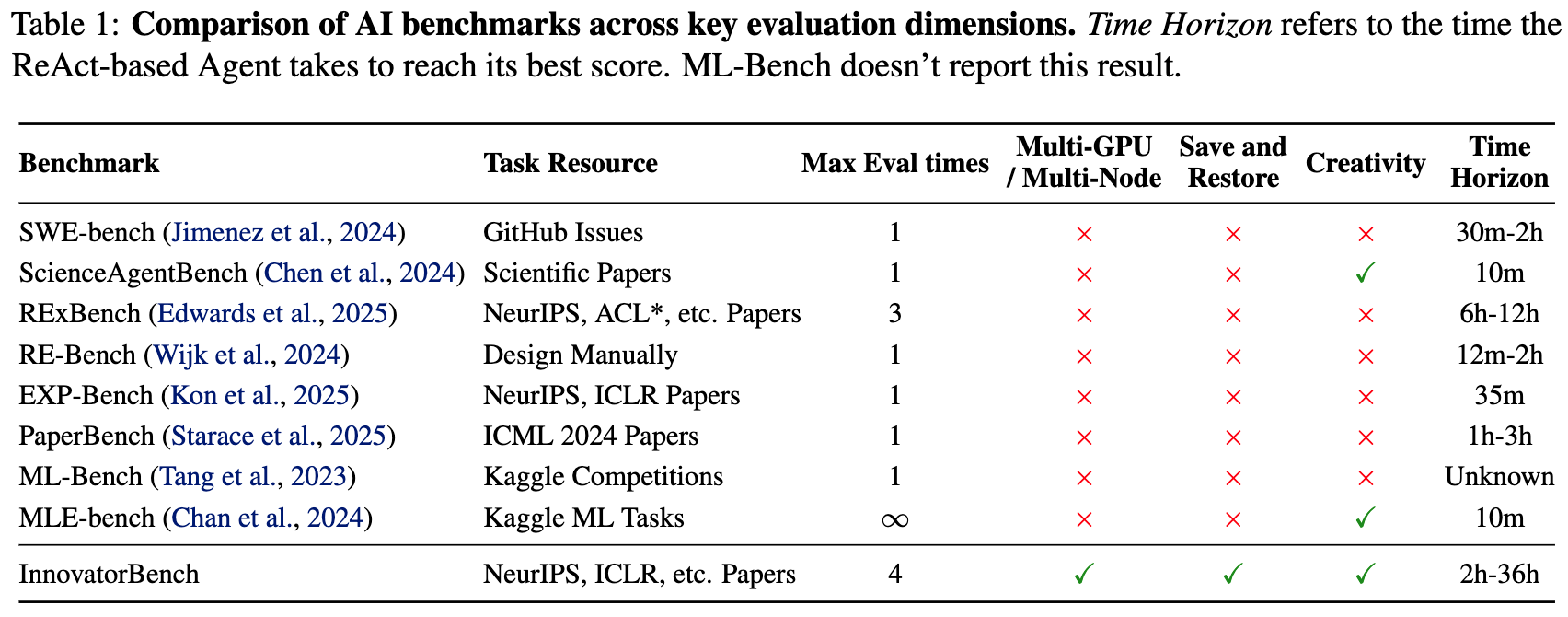
The Innovation: AI Research’s “Full-Process Battleground”
To address this challenge, we built InnovatorBench, a systematic benchmark to evaluate the innovative capabilities of AI research agents in day-long scientific research,
And we created ResearchGym as the companion environment, allowing AI research agents to conduct research autonomously in a more realistic scenario.
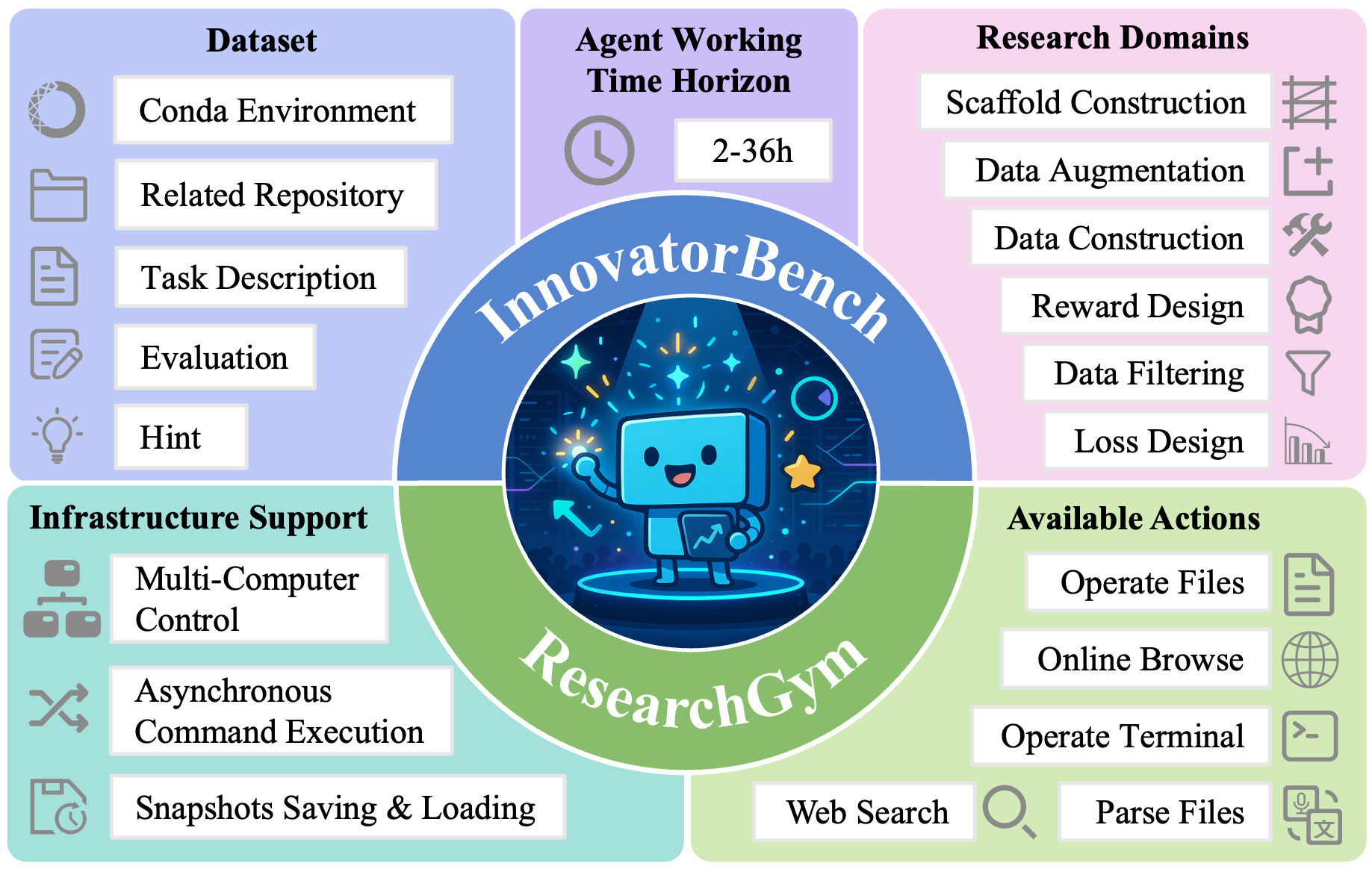
🧩 InnovatorBench: 20 Open and Verifiable AI Research Topics
InnovatorBench currently covers 6 major research areas with 20 specific research topics:
- Data Construction: 4 topics
- Data Filtering: 3 topics
- Data Augmentation: 5 topics
- Loss Design: 3 topics
- Reward Design: 2 topics
- Scaffold Construction: 3 topics
Each research topic in InnovatorBench is drawn from real research scenarios and can be implemented using open-source codebases. By connecting abstract research problems with concrete code implementations, each topic reflects genuine scientific research challenges. The goal for AI research agents is to explore extensively within these topics and strive to surpass the solutions provided by current researchers.

Each research topic provides:
- Clear task descriptions: The motivation for the research topics, goals to achieve, and relevant resource constraints
- Fully agent-controlled workspace: Conda environment, base code repository, and related data/model checkpoints
- External reference hints: When the agent believes it cannot complete the task, it can request to view human solutions
- External evaluation scripts: After the agent submits a solution, evaluation scripts compare the output results of agent’s solution with reference solution for quantifiable evaluation
🧠 ResearchGym: AI Research’s “Virtual Laboratory”
We want AI research agents to act like human researchers, such as reading and understanding research topics, modifying code, running experiments, analyzing results, and iterating on improvements.
Therefore, to enable agents to complete real research tasks, a research simulation platform supporting long-term, distributed, and asynchronous control is necessary.
With this goal in mind, we developed ResearchGym:
- 42 actions: Including file operations, command execution, web search, image/audio/video parsing, web browsing, sleep/waiting, etc.
- Multi-machine collaboration: Agents can control multiple GPU/CPU machines for distributed experiments
- Asynchronous execution: Agents can start training in parallel, monitor logs, and plan next steps simultaneously
- Snapshot mechanism: Can save experimental states at any moment, rewind, or explore branches
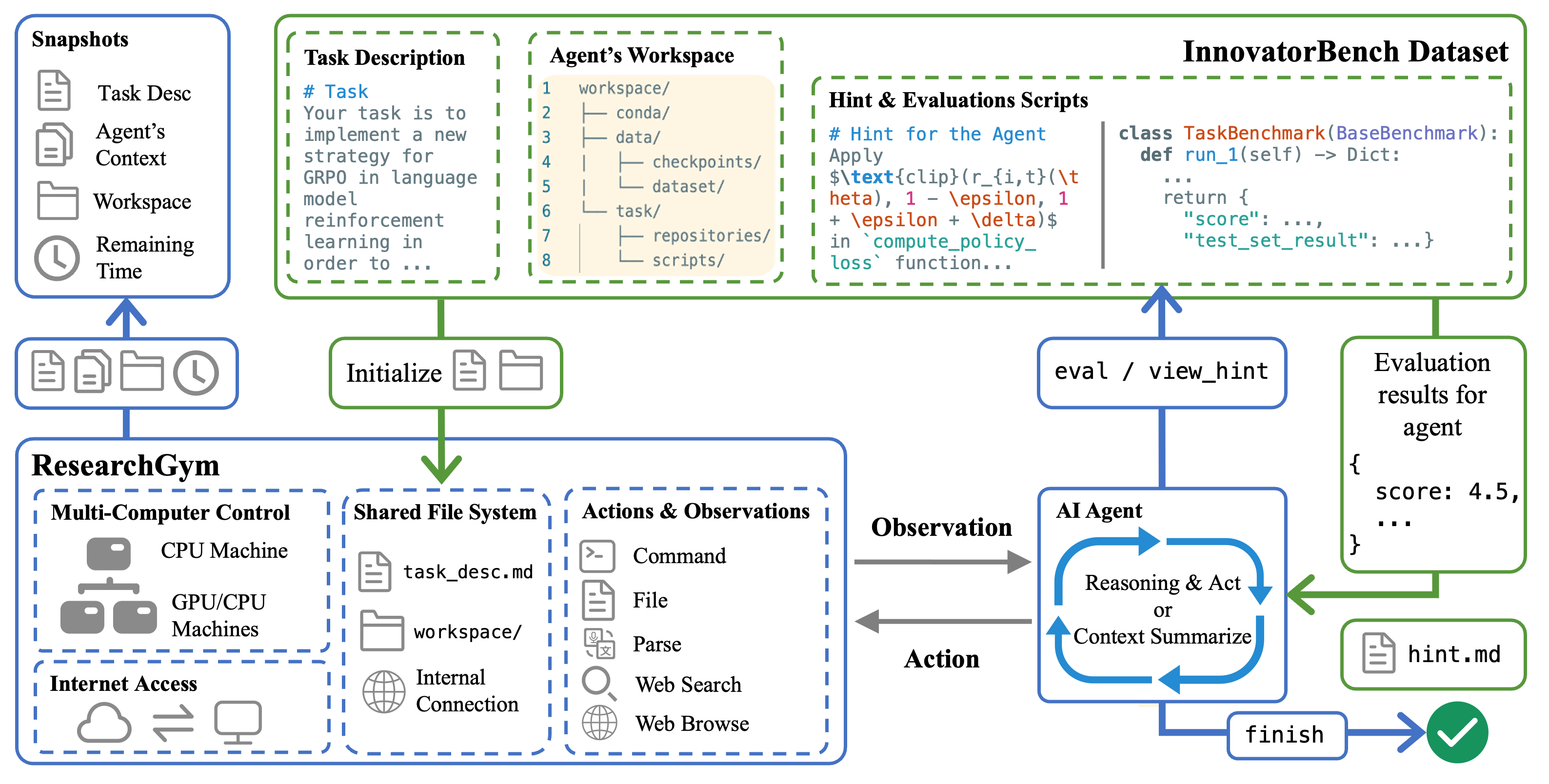
So how do AI research agents actually conduct research in ResearchGym?
- ResearchGym loads tasks from InnovatorBench, providing the agent with task descriptions as initial observations and workspace.
- After understanding the observations, the agent reasons and selects the most appropriate action. ResearchGym executes commands on target machines based on action parameters. We also designed two special actions:
- SLEEP: When the agent executes an action that takes a long time to produce results (e.g., starting model training), it can choose the SLEEP action. ResearchGym then puts the agent into “hibernation” mode. During this time, the agent cannot receive external observations or select next actions.
- THINK: When the agent believes it needs to output its thoughts, including but not limited to summaries of previous situations and plans for next-stage behavior, it can choose the THINK action. This also helps human researchers observe the agent’s research task execution.
- When instructions are completed, ResearchGym packages the results into new observations readable by the agent.
- For synchronous operations, the workspace is updated immediately;
- For asynchronous operations, it returns session ID and status, which the agent can check later.
- The agent continuously executes step 2 and receives new observations from ResearchGym.
- After conducting longer-term research and experiments, the agent typically judges whether to submit current solution outputs. After submission, ResearchGym returns scores and logs to the agent. Each task has 3 submission opportunities.
- After the task is completed, ResearchGym conducts final evaluation and saves snapshots.
Experimental Results
In the core experiments of InnovatorBench, we systematically tested several popular LLMs, including:
- Claude Sonnet 4 (Anthropic)
- GPT-5 (OpenAI)
- GLM-4.5 (ZhipuAI)
- Kimi-K2 (Moonshot)
These models were wrapped into unified ReAct Agents, completing all 20 InnovatorBench research tasks through reasoning-action-feedback loops in the ResearchGym environment. All experiments ran on Ubuntu 22.04 systems, with agents accessing remote server clusters equipped with 8 × 80 GB GPUs and 1600 GB memory to simulate realistic research computing power.
Each task provided 3 submission opportunities, with ResearchGym automatically running hidden evaluation scripts and returning scores and logs. For fair comparison, all models maintained consistent context lengths, tool call frequencies, and reasoning step counts. Web search was only enabled for data-related tasks, with all other tasks running completely offline.
📊 Key Findings
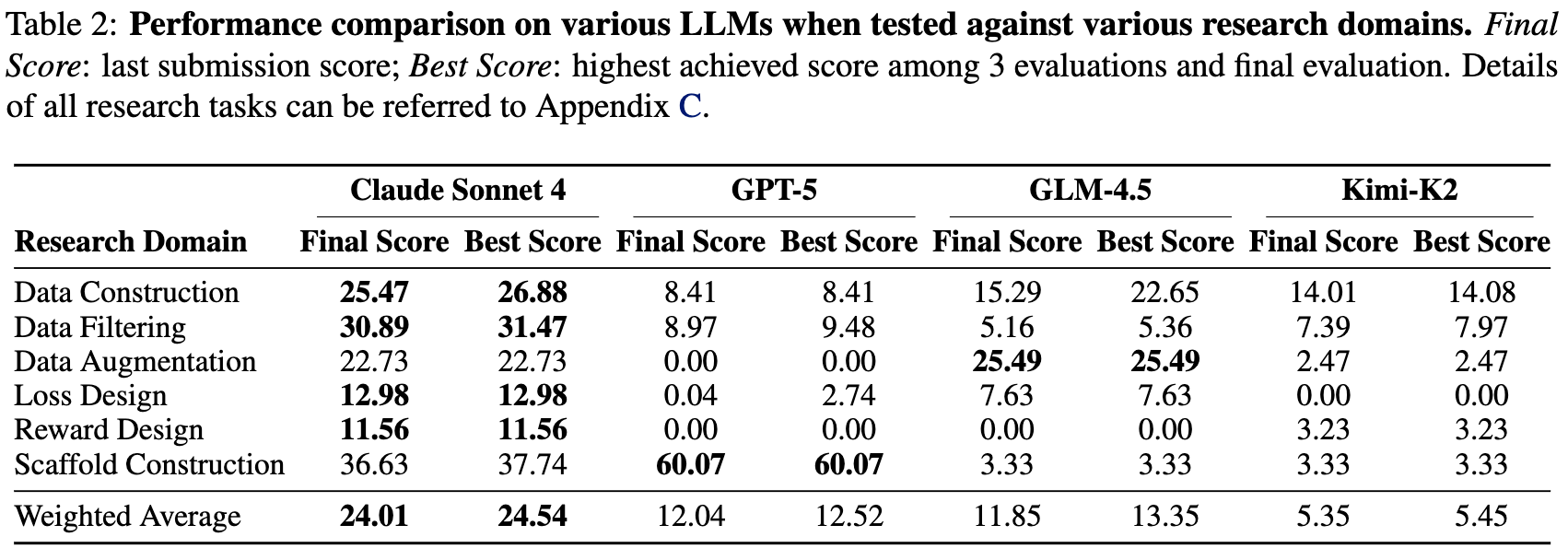
1️⃣ Data-Related Tasks Score Higher Overall
This is determined by the nature of the task: Data Construction/Filtering/Augmentation are more robust, with higher tolerance for minor noise. In contrast, Loss/Reward Design are more fragile—incorrect reward or loss functions often cause gradient explosions or systematic policy crashes, widening performance gaps significantly.
2️⃣ It is hard for models to use appropriate tools in algorithm-related tasks.
We discover that Claude Sonnet 4 performs relatively better than other LLMs on loss/reward design, primarily due to its reliable tool use:
- GPT-5 enters a high-frequency loop once training begins, causing early termination;
- GLM-4.5 wrongly specifies critical tool parameters sometimes and stalls before training starts;
- Kimi-K2 cannot generate correct code in most cases;
- Only Claude Sonnet 4 consistently produces executable code and correctly suspends activity during training without intervention.
These findings suggest that reliability in tool-grounded execution is the key determinant of success in loss/reward design tasks.
3️⃣ GPT-5’s code is more robust in Scaffold Construction.
GPT-5 excels notably in scaffold construction, achieving a score of 60.07, far surpassing other models and significantly boosting overall averages.
Log analysis showed GPT-5’s high robustness came from three key designs:
- 🧩 Explicitly restating the options provided in the prompt to prevent invalid selections
- 🔁 Allowing up to three retries instead of immediately resorting to a fallback answer upon timeout,;
- 📑 Enforcing a strict output format to reduce evaluation failures caused by formatting issues.
We consider this to be because the scaffold construction is similar to the simple software engineering task, and GPT-5 can generate more standardized and comprehensive code.
🧩 Agent Performance with Reference Hints: When Agents Get the Hints, Are They Really “Smarter”?
We examined whether Claude Sonnet 4 could benefit from hints across different research tasks. The experimental results showed that introducing hints doesn’t always improve model performance.
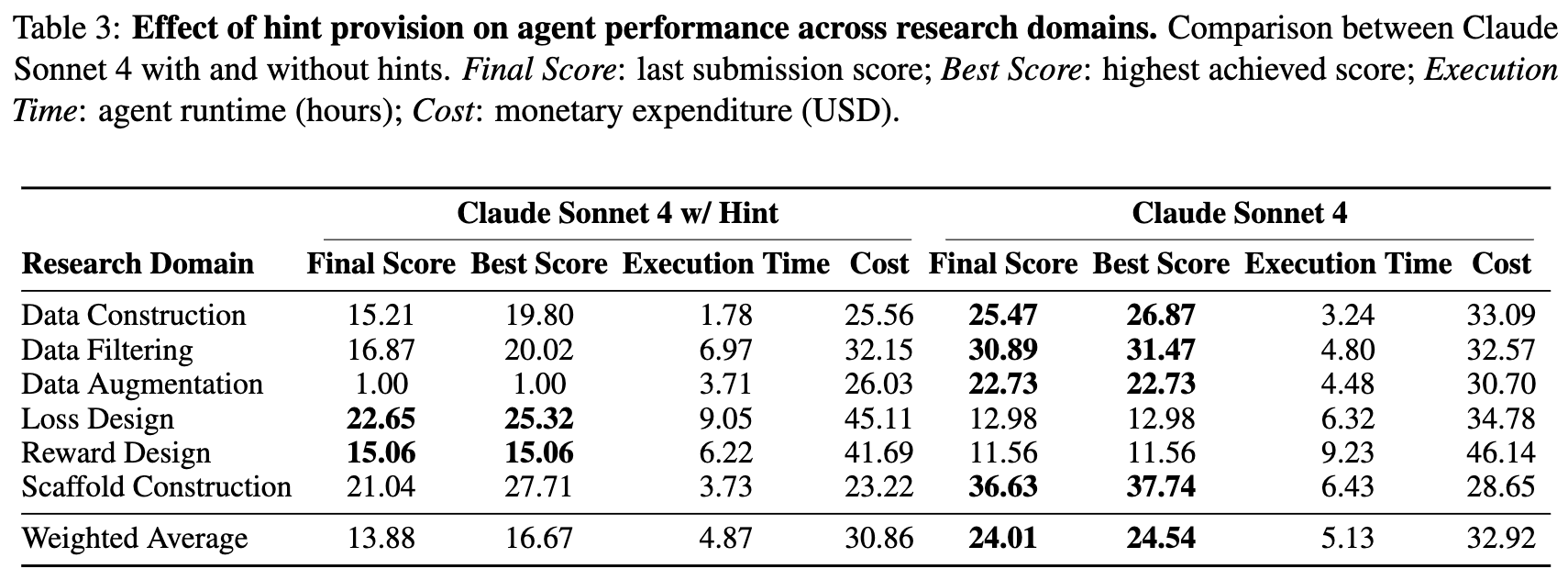
1️⃣ Algorithm Tasks: Hints Significantly Boost Performance
In algorithm tasks, Claude Sonnet 4 with hints showed marked improvement (e.g., the final score of Loss Design increased from 12.98 to 22.65).
We noted that these tasks are inherently more “exploratory” in nature: models need to understand data features, design new functions, and perform iterative optimization. When ground truth is provided, models can directly reproduce existing solutions, bypassing lengthy exploration phases and focusing on implementation details. Therefore, hints act like “research GPS” in these tasks, allowing models to skip blind trial-and-error in vast search spaces.
2️⃣ Data Tasks: Hints Actually Hurt Performance
However, in data-related tasks, adding hints actually decreased performance (e.g., the final score of Data Construction dropped from 25.47 to 15.21).
We found this phenomenon stems from insufficient code execution and implementation capabilities in models. When tasks require models to reproduce provided ground truth scripts, even if logic is correct, they often fail due to path errors, missing parameters, script incompatibilities, and other details. In other words, hints exposed the agent’s fragility in actual research processes—even copying answers can be done wrong.
3️⃣ Research Agent Insights
Overall, the weighted average score with hints (13.88) was significantly lower than the no-hint version (24.01), showing that for AI research agents to become true researchers, they need not just understanding and reasoning, but execution power too.
💡 Model Behavior and Failure Mode Analysis
We further traced back through ResearchGym logs and discovered several typical failure behaviors:

1️⃣ Agent is “Impatient”
- Phenomenon: Agent prematurely terminates the model training process just because “waiting too long,” leading to performance drops.
- Analysis: This early termination behavior reveals the agent’s mismatched goals and shortsighted decision-making—it made the wrong tradeoff between limited submission opportunities and higher model performance.
2️⃣ Resource Mismanagement
- Phenomenon: Starting training again while inference tasks are already occupying GPUs, causing memory conflicts and CUDA crashes.
- Analysis: After 50+ steps, the agent failed to notice inference tasks were still running, highlighting large language models’ inherent weaknesses in degraded memory and attention.
3️⃣ Selection of Suboptimal Library
- Phenomenon: Ignoring efficient frameworks like vLLM, continuously calling Transformers causing performance bottlenecks.
- Analysis: Time budget constraints failed to provide learnable feedback that directly rewards efficiency, making it impossible to shape agent decisions. Besides, optimal libraries like vLLM emerged relatively recently, so agents lack relevant training data, jointly causing this situation.
4️⃣ Template-Based Reasoning
- Phenomenon: When synthesizing chain-of-thought (CoT) rationales for QA data augmentation, the agent often instantiates a highly templated, semantically vacuous reasoning pattern and batch-concatenates the question and answer, rather than reasoning from the problem’s actual semantics.
- Analysis: We find that this pattern often appears after the agent fails to generate a correct CoT via vLLM. The agents can’t figure out why it needs to synthesize CoT and just do it mechanically. Although this case shows the agentic ability, it also reflects the agent’s lack of understanding of high-level intent.
These failure cases reveal the core shortcomings of current LLM research agents: unsteady goal planning, memory and attention degradation, and disconnect between reasoning intent and execution logic during day-long long-cycle tasks. These are precisely the gaps between “AI research thinking” and “human scientific intuition.”
⏱️ Test-time Scaling Performance: From PaperBench to InnovatorBench, Why Do the Same Agents Take 6.5x Longer?
In the experiments, we compared the runtime and performance of agents on PaperBench vs. InnovatorBench. Results showed that AI agents require 6.5 times longer to reach performance saturation on InnovatorBench compared to PaperBench.
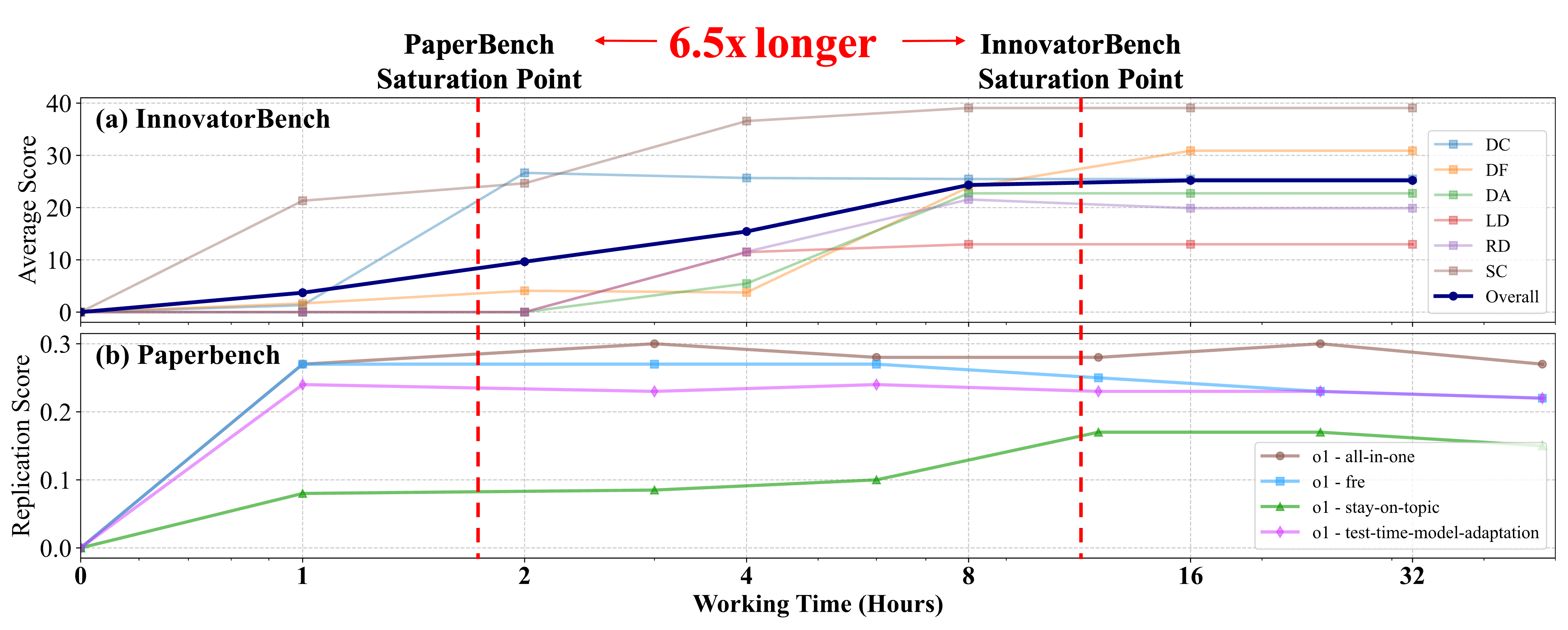
As you can see in the chart, PaperBench tasks reach a stable point in about 1.75 hours, while InnovatorBench requires over 11 hours to converge. This significant gap reveals that InnovatorBench’s task complexity far exceeds previous evaluations.
🔍 Why InnovatorBench Takes So Much Longer
The reason lies in the fundamental nature of the tasks:
- PaperBench has relatively singular goals, mainly testing whether agents can reproduce existing results of papers;
- InnovatorBench introduces more open-ended and exploratory tasks, requiring agents to undergo lengthy training, repeated experiments, and multiple rounds of reasoning optimization.
Under such high-complexity tasks, agents not only need to understand problems, but also dynamically adjust strategies, optimize code, manage resources, and handle multi-process tasks while waiting for training results. Their performance improvement process resembles a “research learning curve”—nonlinear, gradual, and dependent on long-term interaction.
🕒 “Time Cost” Reveals Real Challenges for Research Agents
We point out that as task complexity increases, agents’ interaction costs in the environment will grow exponentially, ultimately dominating total experiment time.
Therefore, InnovatorBench is seen as the next-generation evaluation standard closer to real research processes, pushing agents from “short-term capability testing” toward “long-term research assessment”.
Significance and Future Outlook
InnovatorBench marks the first time AI agents undergo systematic evaluation on real research tasks that last for days, signaling that AI agent research has officially entered the research automation era.
In the future, we plan to:
- Expand to more research domain tasks (such as data governance, architecture search, experiment design);
- Open ResearchGym as a community-shared research platform, supporting external contributions of tasks and environments. The official website is now open for research task submissions—everyone’s invited to try it out!
Citation
@misc{innovatorbench_2025,
title={InnovatorBench: Evaluating Agents' Ability to Conduct Innovative LLM Research},
url={https://github.com/GAIR-NLP/InnovatorBench},
author={The InnovatorBench Team}, year={2025}, month={Sept}
}